mklz-fps
mklz Fast Parallel Sort
Project maintained by firephinx Hosted on GitHub Pages — Theme by mattgraham
Fast Parallel Sort
By: Matthew Lee (mkl1) and Kevin Zhang (klz1)
Summary
We submitted a fast parallel sample sorting algorithm in Go into 15-210’s Sorting Competition by Professor Guy Blelloch. We optimized our implementation for performance on a 72-core machine called Aware and also tested on a variety of other machines such as the 20 core unix machines and the gates machines. After the competition, we analyzed and compared our performance with the provided code from the competition as well as parallel sorting implementations in other languages.
Background
Sorting is a classical problem in computer science. The challenge we had was to correctly optimize the performance of different sorting algorithms on large parallel and distributed machines. The key input and output data structure was an array that needed to be sorted with key value pairs that were both doubles. Sorting is fundamentally not a computationally expensive problem and more of a memory expensive problem. The benefit of parallelization in sorting comes from the ability to sort partitions of the array independently at the same time.
The dependencies in the program depend on the sorting algorithm. For example, with merge sort, the dependencies are like a tree where each branch needs to wait for its adjacent branch to complete before it can merge together and move up to the next merge. The parallelism with merge sort is that we can use fork join parallelism to compute different sections of the tree independently with a work stealing queue.
With sample sort, there are a few initial dependencies where the program needs to first sample elements from the array, sort them, and then determine the splitters between buckets. Then the processors can fill up each bucket in parallel by working on a segment of the array. Finally each bucket can be sorted in parallel.
Approach
Just to reiterate, the challenge was to have the fastest comparison-based sorting algorithm in a garbage-collected language on a 72-core machine with an input of 100,000,000 key value pairs.

After reviewing literature around the fastest parallel sorting algorithms, we decided to implement parallel sample sort in two garbage-collected languages for the competition: Go and Java.
Sample sort is a divide-and-conquer based sorting algorithm that can be thought of as a generalization of quicksort. In sample sort, the input array is first partitioned into buckets such that elements of earlier buckets should come before elements of later buckets in the final ordering, with each core in charge of distributing a certain partition of the original input. The task that remains is to sort the elements within each bucket, a highly parallelizable problem.
This simple algorithm can be implemented in many ways, which we outline below:
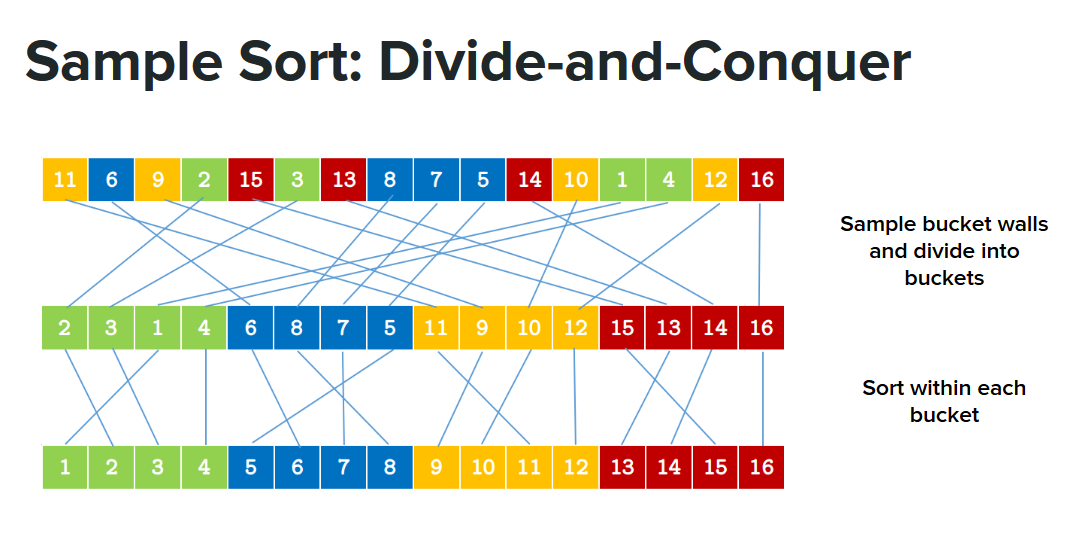
Bucket-counting Stage
In this stage, elements are sampled from the input to act as “splitters”, which define the boundaries between the buckets. Then we divide the input into the buckets in a parallel fashion.
There are two distinct approaches to performing this step. Both approaches begin by dividing the input into blocks, and assigning a thread to each block to count how many elements in that block belong in each bucket. After it is known how many elements from each block belong in each bucket, the offsets for each block within each bucket may be computed and the elements copied from the input sequence to their correct buckets in parallel.
The difference in the two approaches lies in how the bucket-counts for each block are computed. The first approach iterates through each element in the block and binary-searches the list of pivots to determine which bucket the element belongs to. The second approach first sorts the elements in each block and then uses a procedure similar to the “merge” operation in mergesort to count how many elements lie between each pair of pivots.
The first approach - binary search - has the advantage of being O(n log k) per block, where k is the number of pivots and n is the number of elements in the block. Unless each block is really small, this is worse than the complexity of the second approach, which is O(n log n + k). Furthermore, the first approach is non-destructive with respect to the original input, eliminating the need for writes and saving memory bandwidth in the process. We chose to use the first approach for these two reasons.
Distribution stage
- We first implemented the distribution into buckets using fine grained locking with each bucket having its own lock so that the bucket lists wouldn’t run into concurrency issues when two threads add to the same bucket at the same time. We used this as a baseline in our Java program.
- We then tried having each thread make separate lists for each bucket with the elements in its partition and once all the partitions were done, the lists were appended to each other to create the complete buckets, but this took a lot of bandwidth as well as memory.
- Finally, we implemented the distribution into buckets using prefix sums to determine where the buckets start in the array as well as where each partition would start inserting its elements into the buckets. This ended up being much more efficient even though we had to iterate through the entire array twice (once to get the counts for the prefix sums and a second time to transfer the data into the proper positions).
Additionally in Java, we tested different ways of representing the key value pairs. For example, we tried a 2D array, Java’s MapEntry, and creating a new Object. We found that Java was fastest with Objects.
We then experimented with sorting by indices instead of moving the elements around to see if the lower bandwidth could help improve our performance. However, in practice, sorting indices was significantly slower then sorting elements.
Intra-Bucket Sorting Stage
Once the elements have been partitioned and distributed into buckets, all that remains is to sort each bucket. Since each bucket is independent of the others, all buckets can be sorted simultaneously, in parallel. Within each bucket, the Go standard library’s implementation of quicksort is used.
Parameter selection
Although a key feature of Go is lightweight threads, or “goroutines”, that encourage application programmers to spawn many more threads than there are cores, we avoid this style in favour of a low thread-to-core ratio. Having a small number (~2-4) of threads per physical core is high enough that hyperthreading can be used to hide memory-access latency (a huge concern as sorting is bandwidth-bound), but not so high as to incur significant overhead.
Results
Performance was measured by the wall-clock time of sorting 100,000,000 key value pairs that were of type double.
The good news is that we got close to linear speedup: the performance of our algorithm is 88% of the ideal speedup.
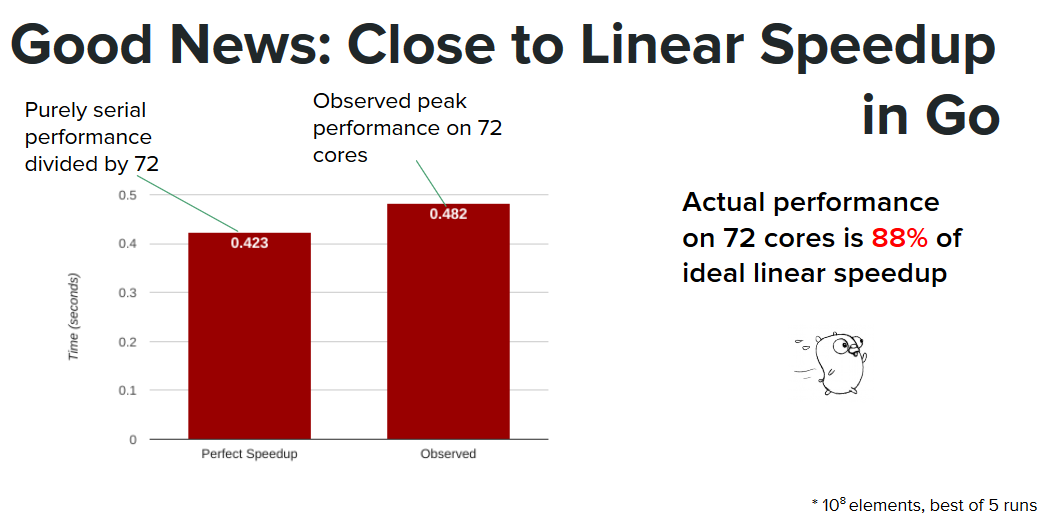
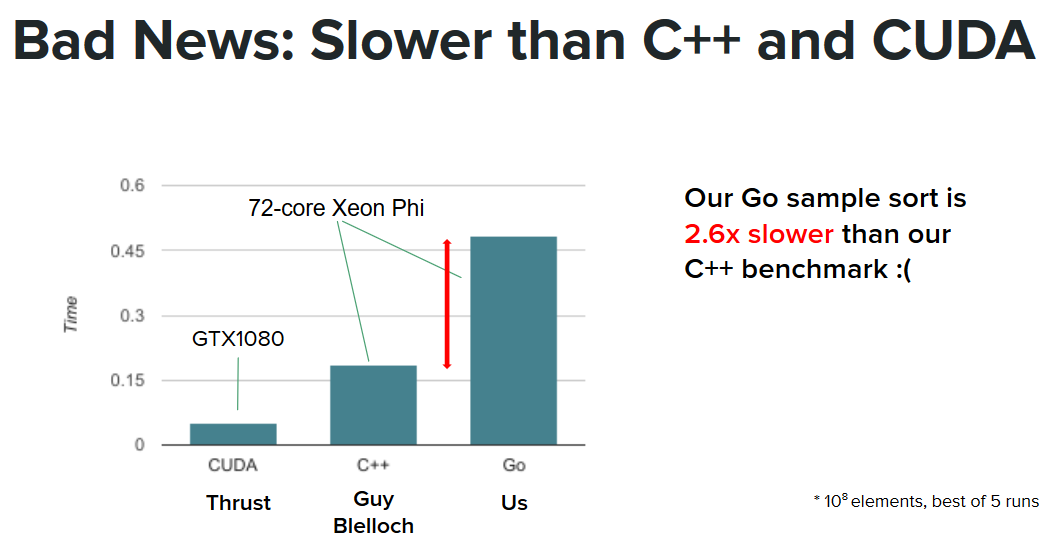
However, we feel that a true challenge - a proper benchmark - is to see how our algorithm stacks up against the best algorithms we knew of, in any language. On the same machine, the baseline C++ written by the 210 team was still 2.6x faster than our Go implementation. In addition, we tested the CUDA sort from the Thrust library on a GPU, a GTX1080, which was able to sort 100 million elements even faster, taking advantage of the higher bandwidth available on the GPU. It should be noted that the timing data for the GPU also includes the time taken to transfer the data to and from the GPU.
On the plus side, however, our Go implementation is 3.6 times faster than the Java library’s built-in parallel sort. Of course, it is much faster than the serial implementations in C++, Go and Java. In particular, it is 63 times faster than the serial implementation in Go.
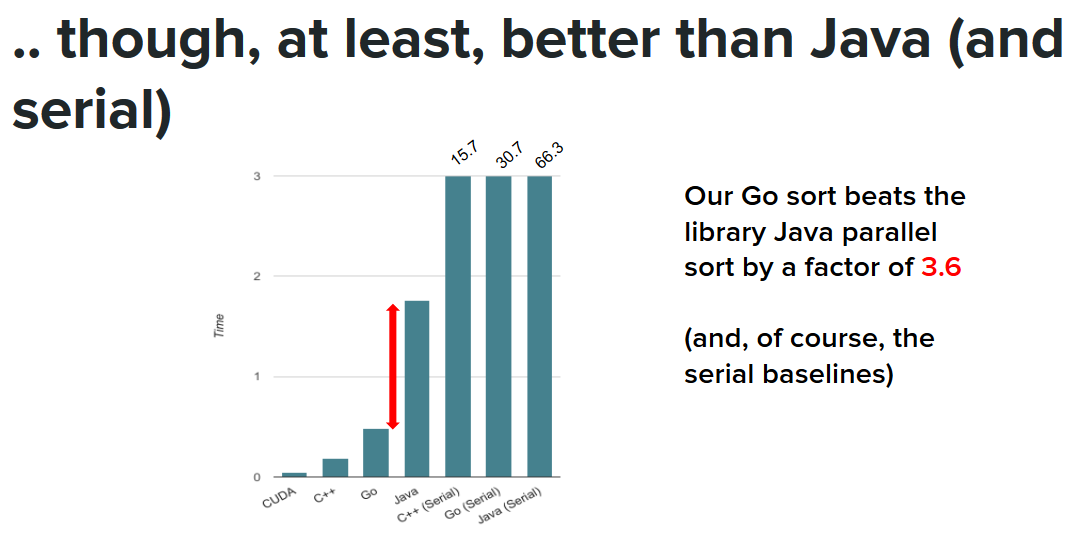
Now, it’s not always sunny in Pittsburgh, which is where the storm comes rolling in. We also tried implementing a similar algorithm in Java. However, we ended up with a vastly different result than Go with our Sample Sort being twice as slow as Java’s built in ParallelSort. From our analysis of the timing, we spent the most time with determining the correct bucket for each element, which is strange because we implemented it with binary search, but perhaps Java’s JIT compiler is unable to optimize for it when each run finds different elements as splitters.
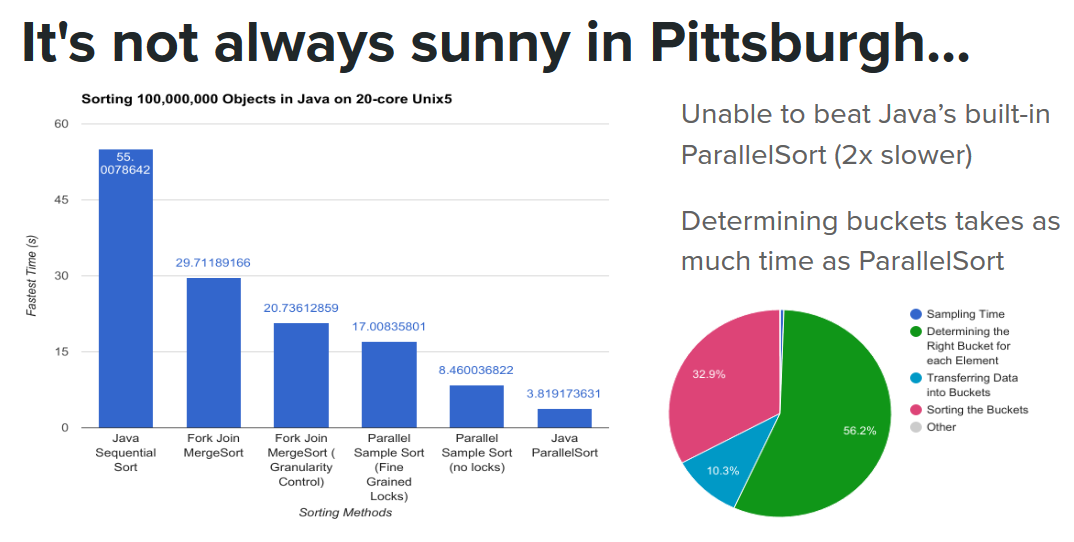
Anti-Optimizations
One “optimization” which we thought might work involves the amount of writes that occur during the intra-bucket sorting stage. Although the elements are structs consisting of two double-precision floats, only one of them, the key field, is used to determine the ordering of elements - the other value, the data field, is not involved in comparisons. Despite this, during sorting, both the key and the data fields are being copied and shuffled around in memory.
We sought to reduce the amount of writes that occur during sorting by sorting indices instead of elements. To sort a bucket of length n, we created an array of 4-byte integers from 0 to n-1, and sorted this list of indices instead. (To determine the order between two indices, we compare the elements they represent). After sorting the indices, we permuted the array of elements in-place to put them in the right order.
Since elements are 16 bytes in size, but indices are only 4 bytes in size, we thought that we would see significant speedup due to less memory bandwidth needed.
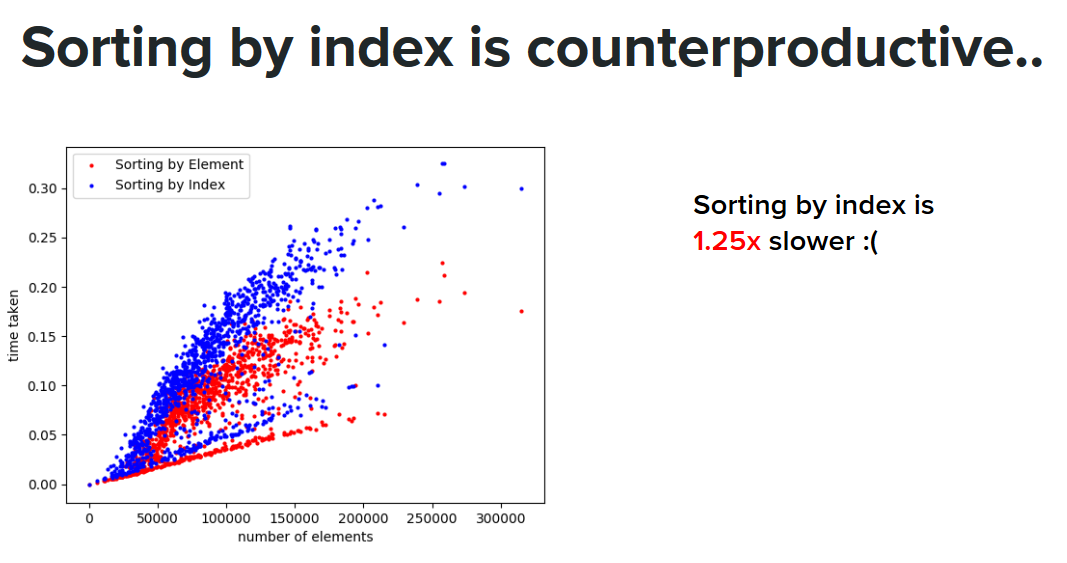
Unfortunately, this was counterproductive, leading to a roughly 1.25x slowdown in the sorting phase.
Delving deeper, we measured the time taken to sort the indices separately from the time taken to permute the actual elements after the indices had been sorted. We discovered that the overhead of permuting the elements, as represented by the green points, was minimal. Sorting the indices alone - the yellow points - took up the bulk of the time.
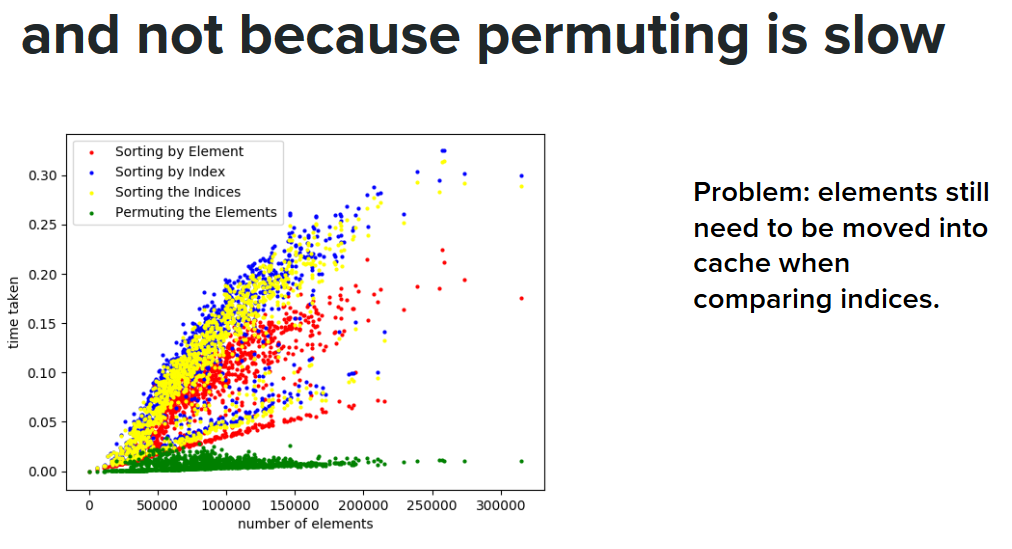
Upon further reflection, we realised that although we had eliminated the need to write elements while indices were being sorted, the fact that they still had to be read from memory in order to compare pairs of indices was preventing us from seeing any speed-up.
Conclusion
Overall, we learned a lot about optimizing sort algorithms on a variety of machines in the two languages and figured out that it might not be as easy as we thought to beat a highly optimized built-in parallel algorithm with a private implementation of TimSort.
References
Axtmann, M., & Sanders, P. (2017). Robust Massively Parallel Sorting. In 2017 Proceedings of the Ninteenth Workshop on Algorithm Engineering and Experiments (ALENEX) (pp. 83-97). Society for Industrial and Applied Mathematics.
Bozidar, Darko, and Tomaz Dobravec. “Comparison of parallel sorting algorithms.” arXiv preprint arXiv:1511.03404 (2015).
Leischner, Nikolaj, Vitaly Osipov, and Peter Sanders. “GPU sample sort.” Parallel & Distributed Processing (IPDPS), 2010 IEEE International Symposium on. IEEE, 2010.
List of Work by Each Student
Matthew wrote all of the Go code while Kevin worked on the Java sorting and CUDA benchmarking programs. In addition, Matthew made the presentation while Kevin worked on the final report.